Hi everyone,
I talked a bit about scriptable objects throughout the devlog but I never really presented my approach. I started using them mainly because I needed to compartmentalize all the settings used for the generation of the forest. I also needed a quick way to create variations of the same set of parameters. Indeed, to handle the different areas that the forest is made of I wanted a way to simply create a new Area file and just change a set of predefined parameters. But I also needed a lot more settings to describe all the trees, rocks and shrubs that fill the different layers of the forest. Without them I'm not sure how I would have done it. They are great to store parameters that you would need in multiple places. Such as for instance the settings describing a layer of trees that was present in more than one area of the forest. Although, to be perfectly honest, I'm not sure my approach was very good because in the end it's kind of a mess :D
First things first, the top level, master of all scriptable objects, contains the settings related to the size and overall organization of the forest. It thus contains all the areas the forest can bear as well as the various kinds of ground surfaces that are available. As can be seen in the screenshot below I also use it to change the distribution of areas and make some areas more or less probable.
 The point of entry into a deep hierarchy of scriptable objects containing scriptable objects containing parameters containing scriptables objects and so on.
The point of entry into a deep hierarchy of scriptable objects containing scriptable objects containing parameters containing scriptables objects and so on.Each area kind is actually a scriptable object that allows me to specify which layers an area should feature as well as the characteristics of its ground. For instance timber areas do not feature any emergent trees whereas sparse areas feature a very shallow understory layer.
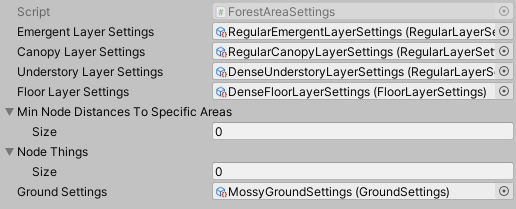 The settings of an area mainly leading to other scriptable objects.
The settings of an area mainly leading to other scriptable objects.And again, thanks to another set of scriptable objects, I can describe the content of each layer and select the forest elements (trees, rocks, bushes, etc.) it should feature. For instance the floor layer of dense areas is full of bushes while most floor layers are usually more sparse or contain a very specific kind of forest element such as rocks or ferns.
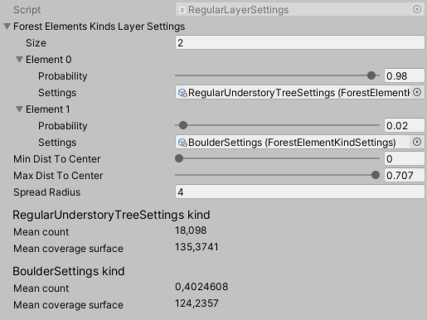 The settings of a given layer can be used to specify the distribution of forest elements.
The settings of a given layer can be used to specify the distribution of forest elements.Of course, the ground settings themselves are stored in another scriptable object. They allow me for instance to specify the amount of leaves or sand that will be visible on the ground or even whether I want some variations of the terrain itself. And a lot of areas share the same ground settings which make these little files very handy.
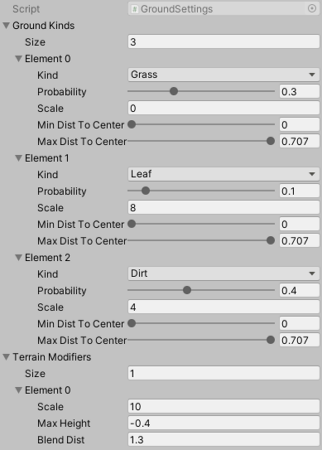 The settings of a given ground will affect the texture and the terrain of the area.
The settings of a given ground will affect the texture and the terrain of the area.Finally (not really), each forest element is described through a set of settings stored in yet another scriptable object. It might seem like a nightmare but you get used to it, I promise. Anyway, each kind of forest element is a scriptable object containing settings such as its range of possible sizes, its effect on the player or in relation to the wind. And depending on the needs of this specific kind it can also require some additional settings. For instance trees require another scriptable object to set their range of possible heights for instance.
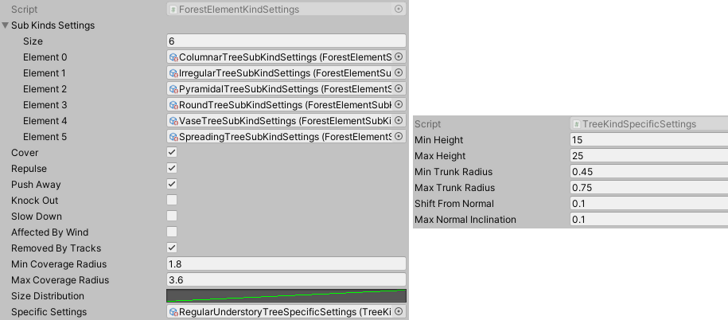 The settings of a given kind of forest element and its specific settings (here those of a tree).
The settings of a given kind of forest element and its specific settings (here those of a tree).But this is not all. I also needed to be able to describe different kinds of trees, some large and tall, others large and round, some with a different set of possible crowns than others. So what did I do?
I added some more scriptable objects!
Basically, all forest elements are described by a scriptable object that contain at least another scriptable object to describe potential variations (sub kinds) of this specific kind but it can also contain a scriptable object that contain specific settings to this kind and its variations. Each sub kind is also represented through a scriptable object that is used to specify the actual object (the prefab) that will be selected for spawning. And again, it is also possible to add another scriptable object to describe specific settings to this sub kind that no other sub kinds has.
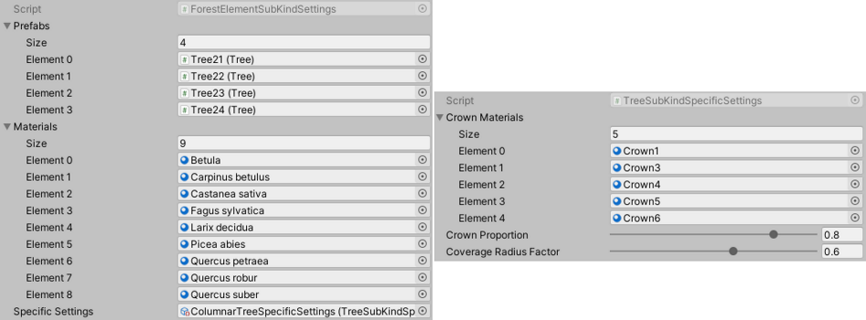 The end to this nightmare: the subkind and its specific settings.
The end to this nightmare: the subkind and its specific settings.This is a lot of parameters stored in a lot of files but this is the best method I've found to handle a collection of parameters that needs to be linked here and there. One of the good thing about these is that I can also use them as Enums. For instance, each kind of forest element (tree, boulder, bush, etc.) is represented by a specific scriptable object that is then passed around and checked against when needed to know the kind of a given object.
The only real issue I had in fact with this scriptable object approach is the retrieval of metadata. Calculating for instance the average radius of the forest elements of a specific area is kind of a pain. With a simple database this would have been very easy through a simple selection query. Instead with scriptable object I need to loop through lists, check types, access another list, loop through it, etc.
 Community
Community
